Chapter 30: Coprocesses
Index
- Introduction
- What is a Coprocess?
- How to create a Coprocess?
- Why is Asynchronous Tricky?
- Alternatives to Coprocesses
- Summary
- References
Introduction
Coprocesses in Bash are a powerful mechanism that allows you to execute commands asynchronously while maintaining a direct communication channel with them. Introduced in Bash version 4, coprocesses enable a script to run a background command or pipeline while interacting with it through dedicated input and output streams. This feature is particularly useful when you need to exchange data dynamically with a running command without blocking your script.
A coprocess is essentially a subprocess that operates in parallel to the main Bash script. When a coprocess is launched, Bash creates two file descriptors: one for writing to the coprocess’s standard input and another for reading from its standard output. This setup allows seamless data exchange between the script and the coprocess, making it an efficient tool for managing complex workflows or integrating external utilities.
What is a Coprocess?
A coprocess is an asynchronous process created using the “coproc” built-in command in Bash.
When a command is executed as a coprocess, it spawns a new process that runs in parallel with the main script or shell. This process is linked to the invoking shell or script through file descriptors, enabling seamless interaction between the two. Specifically, these file descriptors provide access to the coprocess’s standard input and standard output, allowing the main shell or script to send and receive data dynamically.
Curious about how to create a coprocess? That’s exactly what the next section will cover!
How to create a Coprocess?
To create a coprocess in Bash, you use the “coproc command. Its syntax is straightforward:
coproc [NAME] command [redirections]
Executing this command has two significant outcomes. First, the specified command runs asynchronously in a child process, and its standard input and standard output are linked to an array named “NAME”. If no name is specified, the default name “COPROC“[1] is used. This array consists of two positions:
- “
NAME[0]” or “COPROC[0]:: Contains the file descriptor for reading the standard output of the coprocess. - “
NAME[1]” or “COPROC[1]”: Contains the file descriptor for writing to the standard input of the coprocess.
The second outcome is the creation of an environment variable to store the PID of the coprocess. If a name is provided, the variable will be “NAME_PID”; otherwise, it defaults to “COPROC_PID”.
Visually, a coprocess links the main script (or calling shell) with the child process via file descriptors. These descriptors enable the script to read data from the coprocess’s output and send data to its input seamlessly. If you use a custom name with “coproc”, the array and PID variable are adjusted accordingly to reflect the specified name.
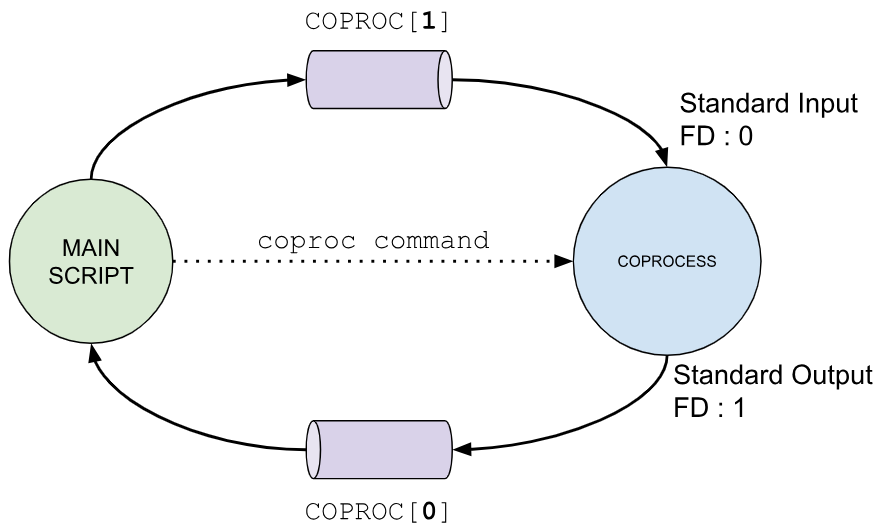
or
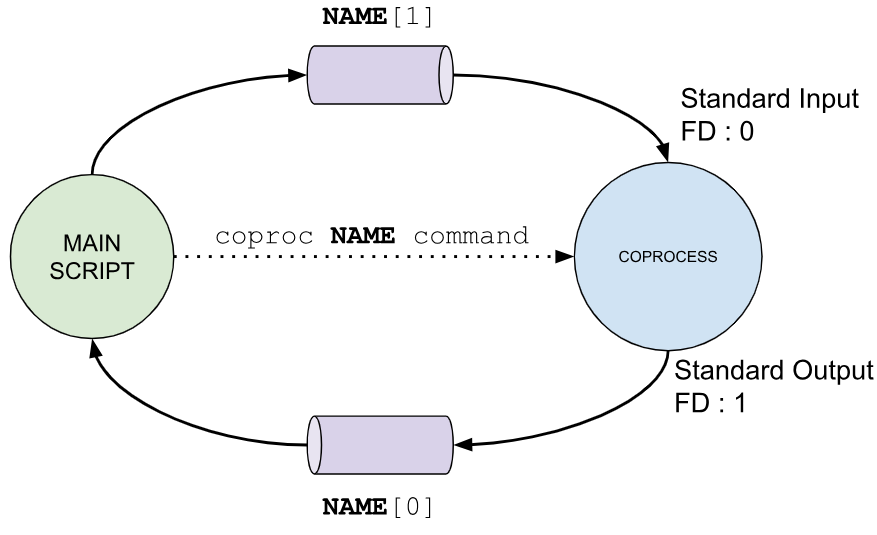
in the case of specifying the name for the file descriptor array.
For a practical example, imagine we create a folder with some files and write a Bash script that sets up a coprocess to interact with the Bash shell. Using this coprocess, the script sends commands for execution and processes the results dynamically. Preparing the folder and running the script demonstrates the power and simplicity of coprocesses in real-world scenarios.
$ mkdir coprocess
$ cd coprocess
$ touch{1..10}.txt
$ ls
file10.txt file1.txt file2.txt file3.txt file4.txt file5.txt file6.txt file7.txt file8.txt file9.txt
$
Now let’s write a Bash script to practice our Coprocesses skill:
1 #!/usr/bin/env bash
2 #Script: coprocess-0001.sh
3 # Creating the coprocess
4 coproc MY_BASH { bash; }
5 echo "ls -l coprocess; echo \"-END-\"" >&"${MY_BASH[1]}"
6 is_done=false
7 while [[ "$is_done" != "true" ]]; do
8 read var <&"${MY_BASH[0]}"
9 if [[ "$var" == "-END-" ]]; then
10 is_done="true"
11 else
12 echo $var
13 fi
14 done
15 echo "DONE"
Which produces the following output in your terminal window:
$ ./coprocess-0001.sh total 0 -rw-rw-r-- 1 username username 0 Dec 21 07:16 file10.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file1.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file2.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file3.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file4.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file5.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file6.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file7.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file8.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file9.txt DONE $
Let’s go line by line analyzing the script we just wrote.
In line 4, the “coproc” command is used to create a coprocess running a new Bash shell. This setup enables the script to send commands directly to the coprocess for execution.
In line 5, two commands are sent to the Bash coprocess. The first command, “ls -l coprocess”, lists the files in the “coprocess” directory. The second command, “echo \"-END-\"”, serves as a delimiter. Why is this delimiter necessary? It provides a clear marker indicating when the script should stop reading output from the coprocess. Without such a convention, the script wouldn’t know when to stop waiting for data, potentially causing it to hang indefinitely while trying to read more output.
Between lines 7 and 14, a “while” loop handles the interaction with the coprocess. In line 8, it reads the coprocess’s standard output. Line 9 checks whether the delimiter (“-END-”) has been encountered, signaling that the script should stop reading further output. If the delimiter hasn’t been reached, line 12 ensures that the output is printed back to the script’s standard output.
This example demonstrates a simple but effective way to leverage coprocesses in Bash, showcasing how they can facilitate asynchronous interactions and process control.
Let’s see another example where we will interact with a “python” coprocess. In the following example we will create a coprocess for python and we will send commands to it:
1 #!/usr/bin/env bash
2 #Script: coprocess-0002.sh
3 # Creating the coprocess
4 coproc MY_PYTHON { python -i; } 2>/dev/null
5 # Priting the PID of the coprocess
6 echo "Coprocess PID: $MY_PYTHON_PID"
7 # Defining functions
8 echo $'def my_function():\n print("Hello from a function")\n' >&"${MY_PYTHON[1]}"
9 # Calling the function defined
10 echo $'my_function()\n' >&"${MY_PYTHON[1]}"
11 echo $'my_function()\n' >&"${MY_PYTHON[1]}"
12 echo $'print("-END-")\n' >&"${MY_PYTHON[1]}"
13 # Loop that processes the output of the coprocess
14 is_done=false
15 while [[ "$is_done" != "true" ]]; do
16 read var <&"${MY_PYTHON[0]}"
17 if [[ $var == "-END-" ]]; then
18 is_done="true"
19 else
20 echo $var
21 fi
22 done
As in previous examples, line 4 demonstrates the creation of a named coprocess. Notably, the “-i“[2] flag is used here to enable Python’s interactive mode, allowing the coprocess to accept and execute commands interactively.
Additionally, you’ll observe that standard error is redirected to “/dev/null”. This is done to suppress Python’s startup messages, such as version details and compiler information, which are irrelevant in this context. By redirecting this output, we ensure a cleaner and more focused result.
In line 6, the script prints the PID of the coprocess using the environment variable “MY_PYTHON_PID”, which is automatically generated by the “coproc” command.
In line 8, a Python function is sent to the coprocess. Later, in lines 10 and 11, this function is invoked, demonstrating how the coprocess can execute predefined logic.
Finally, in line 12, a delimiter is sent to signal the end of the output from the coprocess. Lines 14 through 22 then use the same approach as earlier examples to read and process the coprocess’s output, ensuring proper handling of the data generated.
Now if we run the “coprocess-0002.sh” script we will see something like the following in our terminal window:
$ ./coprocess-0002.sh Coprocess PID: 2021770 Hello from a function Hello from a function $
If we had not added the redirection “2>/dev/null” to the “coproc” command our output would have been something like the following:
$ ./coprocess-0002.sh Coprocess PID: 2022737 Python 3.11.0 (main, Jun 22 2024, 21:15:14) [GCC 13.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> ... ... >>> >>> >>> >>> >>> >>> >>> Hello from a function Hello from a function $
As you can see this is more difficult to read than the previous execution with the standard error redirection.
Why is Asynchronous Tricky?
As discussed in earlier sections, a coprocess is an asynchronous program that runs in a child process. However, its asynchronous nature means there are no guarantees about when it will complete. For instance, in previous examples, we relied on a convention to signal the end of the coprocess’s output.
In those cases, the coprocess remained active and ready to receive additional input. But what happens if the coprocess finishes execution, and we attempt to read from its now-closed standard output? Let’s explore this scenario with a simple example where a coprocess lists the contents of the “coprocess” directory:
1 #!/usr/bin/env bash
2 #Script: coprocess-0003.sh
3 # Creating the coprocess
4 coproc MY_LS { ls -l coprocess; }
5 echo "Coprocess PID: $MY_LS_PID"
6 while read var <&"${MY_LS[0]}"; do
7 echo $var
8 done
When this script is executed, the output might look like this:
$ ./coprocess-0003.sh
Coprocess PID: 2152412
total 0
-rw-rw-r-- 1 username username 0 Dec 21 07:16 file10.txt
-rw-rw-r-- 1 username username 0 Dec 21 07:16 file1.txt
-rw-rw-r-- 1 username username 0 Dec 21 07:16 file2.txt
-rw-rw-r-- 1 username username 0 Dec 21 07:16 file3.txt
./coprocess-0003.sh: line 6: "${MY_LS[0]}": Bad file descriptor
$
What’s going on here? Although the directory contains 10 files, the script only displays 4. This happens because the “ls -l coprocess” coprocess completes its execution and closes its file descriptors before the main script has a chance to fully read its output. As a result, the script encounters an error when attempting to access the standard output on line 6.
How can this issue be resolved? One effective solution is to duplicate the coprocess’s standard output file descriptor. By creating a copy, we ensure that the file descriptor remains open even after the coprocess terminates, allowing the main script to process the entire output. Here’s an updated version of the script that implements this approach:
1 #!/usr/bin/env bash
2 #Script: coprocess-0004.sh
3 # Creating the coprocess
4 coproc MY_LS { ls -l coprocess; }
5 # Copy stdout to file descriptor 5
6 exec 5<&${MY_LS[0]}
7 # Print Process ID of the coprocess
8 echo "Coprocess PID: $MY_LS_PID"
9 # Read from file descriptor 5
10 while read -u 5 var; do
11 echo $var
12 done
13 # Close file descriptor 5
14 exec 5<&-
In this revised script, we’ve introduced logic on line 6 to duplicate the standard output of the coprocess to a new file descriptor (e.g., file descriptor 5). We also updated line 10 to read from the duplicated file descriptor and added proper resource management by closing it on line 14.
When this improved script is executed, the output correctly reflects all the files in the directory:
$ ./coprocess-0004.sh Coprocess PID: 2155393 total 0 -rw-rw-r-- 1 username username 0 Dec 21 07:16 file10.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file1.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file2.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file3.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file4.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file5.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file6.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file7.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file8.txt -rw-rw-r-- 1 username username 0 Dec 21 07:16 file9.txt $
In the next section, we’ll explore alternatives to coprocesses for scenarios where their use may not be viable.
Alternatives to Coprocesses
If, for some reason, you’re unable to use coprocesses—perhaps due to an older version of Bash—a viable alternative is to use redirections with FIFO files.
Essentially, a coprocess creates a child process for a given command and connects its standard input and output to specific file descriptors in an array. The file descriptor at position zero of the array is used to read the coprocess’s standard output, while the one at position one is used to write to its standard input.
This behavior can be replicated using FIFO files and subshells. Let’s look at an example where we adapt the script “coprocess-0002.sh” to use FIFO files and subshells:
1 #!/usr/bin/env bash
2 #Script: coprocess-0005.sh
3 INPUT=inputFifo
4 OUTPUT=outputFifo
5 #Creating fifo files
6 mkfifo $INPUT
7 mkfifo $OUTPUT
8 # Creating subshell with python
9 ( python -i ) <inputFifo >outputFifo 2>/dev/null &
10 #Saving the PID of the python subshell
11 PID_PYTHON_JOB=$!
12 # Print Process ID of python subshell
13 echo "PID Python Job: $PID_PYTHON_JOB"
14 # Define funxtion
15 echo $'def my_function():\n print("Hello from a function")\n' >$INPUT
16 # Calling the function defined
17 echo $'my_function()\n' >$INPUT
18 echo $'my_function()\n' >$INPUT
19 echo $'print("EOD")\n' >$INPUT
20 # Lopp taking care of the output of the subshell
21 is_done=false
22 while [[ "$is_done" != "true" ]]; do
23 read var <$OUTPUT
24 if [[ $var == "EOD" ]]; then
25 is_done="true"
26 else
27 echo $var
28 fi
29 done
30 # Cleaning
31 exec 2>/dev/null
32 kill -9 $PID_PYTHON_JOB
33 rm $INPUT
34 rm $OUTPUT
What’s Happening in This Script?
- Setting Up Variables and Creating FIFOs (Lines 3–7): We define variables to hold the names of the FIFO files and then create them using the mkfifo command.
- Creating a Subshell (Line 9): A subshell is launched with its standard input attached to the FIFO file “
inputFifo” and its standard output connected to “outputFifo”. The standard error is discarded, and the subshell is created as a background job[3]. - Storing the Subshell’s PID (Line 11): The PID of the background job is saved in the variable “
PID_PYTHON_JOB”. - Sending Python Code to the Subshell (Lines 15–19): The Python code is sent to the subshell’s standard input via the “
inputFifo” FIFO file. - Reading Output from the Subshell (Lines 21–29): The output from the Python subshell is read via the “
outputFifo” FIFO file. - Cleaning Up (Lines 31–34):
- Standard error is redirected to “
/dev/null” to suppress any unimportant messages. - The background process is terminated using the stored PID.
- The FIFO files created earlier are removed.
- Standard error is redirected to “
When the script is executed, the output resembles the following:
$ ./coprocess-0005.sh PID Python Job: 2159608 Hello from a function Hello from a function $
This demonstrates that it’s entirely possible to replicate the functionality of coprocesses using FIFO files and subshells, providing a workaround for situations where coprocesses are unavailable.
Summary
Coprocesses in Bash are a powerful feature that allows you to run an asynchronous child process and communicate with it through dedicated file descriptors. By using the “coproc” command, you can create a coprocess and access its standard input and output via an array of file descriptors. These file descriptors enable bidirectional communication, with the descriptor at position 0 used to read the coprocess’s output and the one at position 1 used to send input. Each coprocess also automatically creates an environment variable named “NAME_PID” (or “COPROC_PID” if no name is provided) that stores the process ID of the coprocess, making it easier to manage and track.
Since coprocesses run asynchronously, you must handle their completion and output carefully. A common strategy is to use a delimiter, such as a specific string, to mark the end of the coprocess’s output and prevent the main script from waiting indefinitely. Additionally, if the coprocess finishes before its output is fully read, it closes its file descriptors, which can cause errors in the parent script. To avoid this, you can duplicate the coprocess’s file descriptors, ensuring the parent script retains access to the output even after the coprocess terminates. Proper resource management, such as closing unused file descriptors, is also essential for efficient scripting.
In situations where coprocesses cannot be used, such as with older Bash versions, FIFO files (named pipes) and subshells offer a viable alternative. This approach replicates the functionality of coprocesses by redirecting input and output through named pipes, allowing communication with a background subshell. While this method requires additional setup, such as creating and managing FIFO files, it demonstrates the flexibility of Bash scripting for interprocess communication. Whether through native coprocesses or workarounds, Bash provides robust tools for managing concurrency and asynchronous tasks.
“Learning about coprocesses is your ticket to mastering asynchronous operations in Bash.”
References
- https://copyconstruct.medium.com/bash-coprocess-2092a93ad912
- https://unix.stackexchange.com/questions/507786/run-command-in-background-with-foreground-terminal-access
- https://web.archive.org/web/20151221031303/http://www.ict.griffith.edu.au/anthony/info/shell/co-processes.hints
- https://wiki.bash-hackers.org/syntax/keywords/coproc
- https://www.gnu.org/software/bash/manual/html_node/Coprocesses.html
- https://www.linuxjournal.com/content/bash-co-processes
- https://www.linuxjournal.com/content/investigating-some-unexpected-bash-coproc-behavior
1. The advantage of using a “NAME” for the coprocess is that you can create several coprocesses with different names. If you do not specify a name, you can only create a single coprocess which will be associated with the array named “COPROC”.↩
2. More about this Python flag in the following link https://www.python-engineer.com/posts/python-interactive-mode/. ↩
3. Did you see the “&” character at the end of line 9? In a previous chapter we learnt that we can use that character to create jobs.↩